Getting Started With Fides — Step 1: Annotating Resources
Overview
What Is Annotation?
In this three-part blog series, we get to the why and the how of building Privacy-as-Code. That is, we’ll explore the process by which you can describe privacy behaviors in your code, and we’ll highlight the underlying reasons for making these proactive design choices.
In this blog, we’ll discuss annotation, the means by which you can describe the privacy behaviors in your codebase, such as:
- What personal data is this app collecting?
- For the kinds of personal data that my app collects, what is the associated risk that individuals will be identified?
- What are the business purposes for processing this personal data?
- What kind of data subjects (e.g., customers) are contributing their data?
Before jumping into the annotation process, it’s important to grasp the multiple reasons for annotating with fidesctl in the first place.
Why Annotate?
The Functional Reason for Annotation: Fueling Fidesctl’s Privacy-as-Code Power
By annotating your Dataset and System resources with their privacy behaviors, you enable automated checks against privacy policies within CI pipelines. This means that you and your team will be notified of policy violations and privacy risks before code is ever deployed.
For instance, the application might need to abide by an in-house policy or regulation that prohibits the use of users’ identifiable personal data for advertising purposes. Suppose you notice code that fails to comply with this rule only after it’s been deployed and now processing users’ data—how much simpler, less expensive, and less risky if you had addressed this issue back in development! That’s where annotations come in. They enable you to build and verify privacy from the start, a design choice that will persist into runtime.
The Business Reason for Annotation: Your Users are Entrusting You with Their Data
Respect isn’t just an ideal for a system to reflect for its end-users. It’s also a business choice with distinct benefits. Users want to do business with trustworthy companies. From the EU’s GDPR to California’s CCPA, privacy regulations are imposing strict requirements on technical systems, with fines and reputational damage on the line. An estimated 65% of the world’s population will be covered by a general privacy law by 2023.

Data annotation using the open-source Fides toolset is an important first step towards deriving the benefits of true Privacy-by-Design in your infrastructure. Let’s get annotating!
Throughout this series, we’ll use a simple example to illustrate the function and power of Privacy-as-Code. Suppose you have an e-commerce application with the following functions:
- Register a new user.
- Login as a user.
- Sell and purchase products.
- Delete or update products that have been posted.
With this app, your application infrastructure includes:
- Flask to run a web server that simulates the e-commerce app
- PostgreSQL as the app database
- SQLAlchemy to connect to the database
fidesctlto declare privacy manifest and to conduct policy evaluations
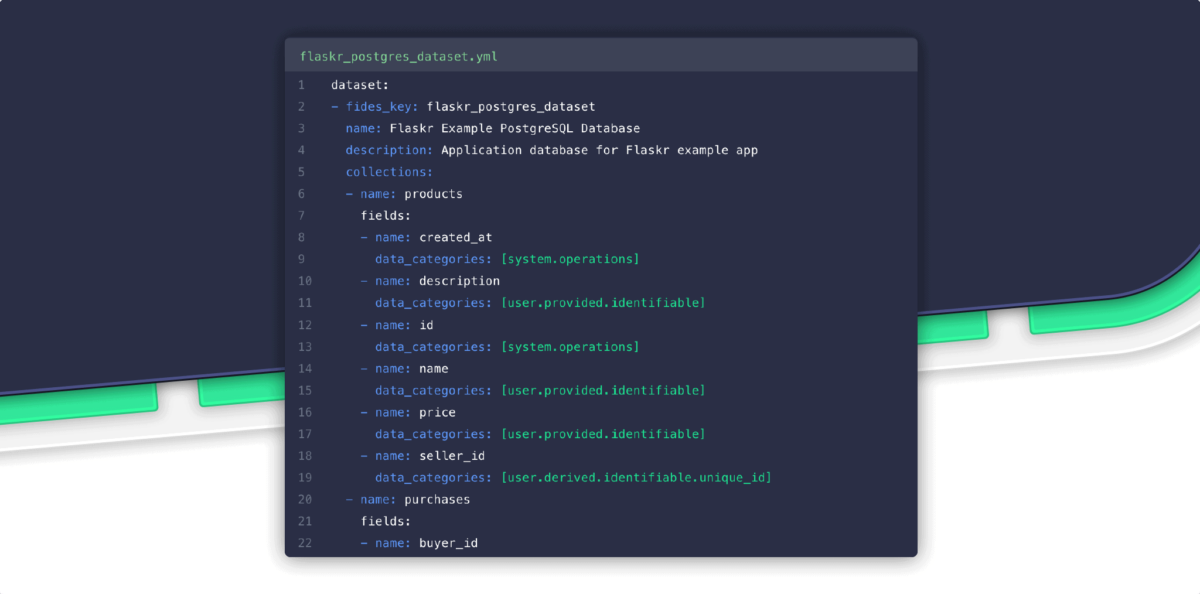
The schema has the following structure:

What are Resources in Fides?
Fides organizes data infrastructure into a hierarchy of resources. At the root is the Organization, which contains all parts of a company or enterprise and the policies the Organization’s sub-resources must follow. While a company could have multiple Organizations, perhaps to categorize their data processing into EU and non-EU countries, the Organizations do not share their sub-resources. So policies in one Organization cannot refer to policies in another Organization.
> Organization
> Registry (optional)
> System
One level below the root, there is an optional level called Registry, which is a collection of Systems. We’ll discuss Systems in detail shortly. They describe data processing activities and the role of Datasets in those activities. A Dataset combines a database schema with Fides privacy categorizations. Each Dataset is represented as a set of Collections (tables), which themselves contain Fields (columns). Datasets support granular annotations of privacy behaviors: what data you are storing and where that data is stored.
> Dataset
> Collections
> Fields
In Fides, Datasets abstract away any database-specific details, so they are agnostic to whether the e-commerce app uses Postgres, MongoDB, or other databases. This way, Datasets can contain privacy categorizations for a variety of databases, feeding privacy metadata into other tooling. We’ll get to the System resource shortly. First, let’s annotate a Dataset.
Annotating a Dataset
With our example e-commerce app, we have our PostgreSQL database. In order to make annotations, we must create a Dataset resource. We add a YAML file to our directory of Fides resources to describe this Dataset and its internal structure. Fides has a feature to automatically create a YAML file for you to annotate, according to the database schema (more on this in the support documentation)
We are then guided by a basic question: “In this dataset, what data categories are stored?” From there we ask, “How is the data protected?” For every Field (column), use the Fides language (fideslang) taxonomy to describe the data categories and data qualifiers.

For instance, a password has the data category
user.provided.identifiable.credentials.password
and the data qualifier
aggregated.anonymized.unlinked_pseudonymized.pseudonymized.
We are using Fides syntax to categorize data within an organized hierarchy.
Continue with this process for your other databases: creating Dataset resources and providing the appropriate attributes to give a robust layer of privacy metadata throughout your data infrastructure.
Annotating a System
A System describes anything that processes data. This could be third-party APIs, services, etc. In a System resource, we can describe a rich layer of privacy metadata. Like Datasets, we describe data categories and data qualifiers. Furthermore, we describe use cases and data subjects according to the Fides taxonomy:
- Use cases: why is this data being processed?
- Data subjects: whose data is being processed?
Returning to our example e-commerce app, we have a single Flaskr Web Application system, and that calls for a System resource. We add a YAML file to the directory of Fides resources with a privacy declaration that describes all four of the above primitives.

Maintain Annotations as Infra Evolves
As your business activities evolve, so will your data infrastructure and your use cases for processing personal data. Incorporate annotation updates, at both the Dataset and System level, into your team’s routine development processes. In doing so, you ensure that the automated privacy checks run in the CI pipeline reflect the most up-to-date data infrastructure. As maintainers of Fides, increased tooling for increasing efficiency in the annotation phase is an important part of Ethyca’s roadmap.
With your Datasets and Systems annotated, you can then start to formalize policies that can be enforced in CI. The next blog post explores the policy creation process.
Learn More and Get Involved
Explore the rest of this three-part blog series to get acquainted with Fides:
To dive deeper into the Fides ecosystem and connect with the Fides open-source community, check out these resources:
- Explore our support documentation.
- Join our Slack community.
- Clone the Fides repo.
- Read our CEO Cillian’s trilogy of articles explaining the underlying structure of the Fides language.